OpenAI is pleased to announce the latest iteration of Whisper, called large-v3. Whisper-v3 has the same architecture as the previous large models except some minor differences.
The large-v3 model is trained on 1 million hours of weakly labeled audio and 4 million hours of pseudolabeled audio collected using large-v2. The model was trained for 2.0 epochs over this mixture dataset.
The large-v3 model shows improved performance over a wide variety of languages, and the plot below includes all languages where Whisper large-v3 performs lower than 60% error rate on Common Voice 15 and Fleurs, showing 10% to 20% reduction of errors compared to large-v2:
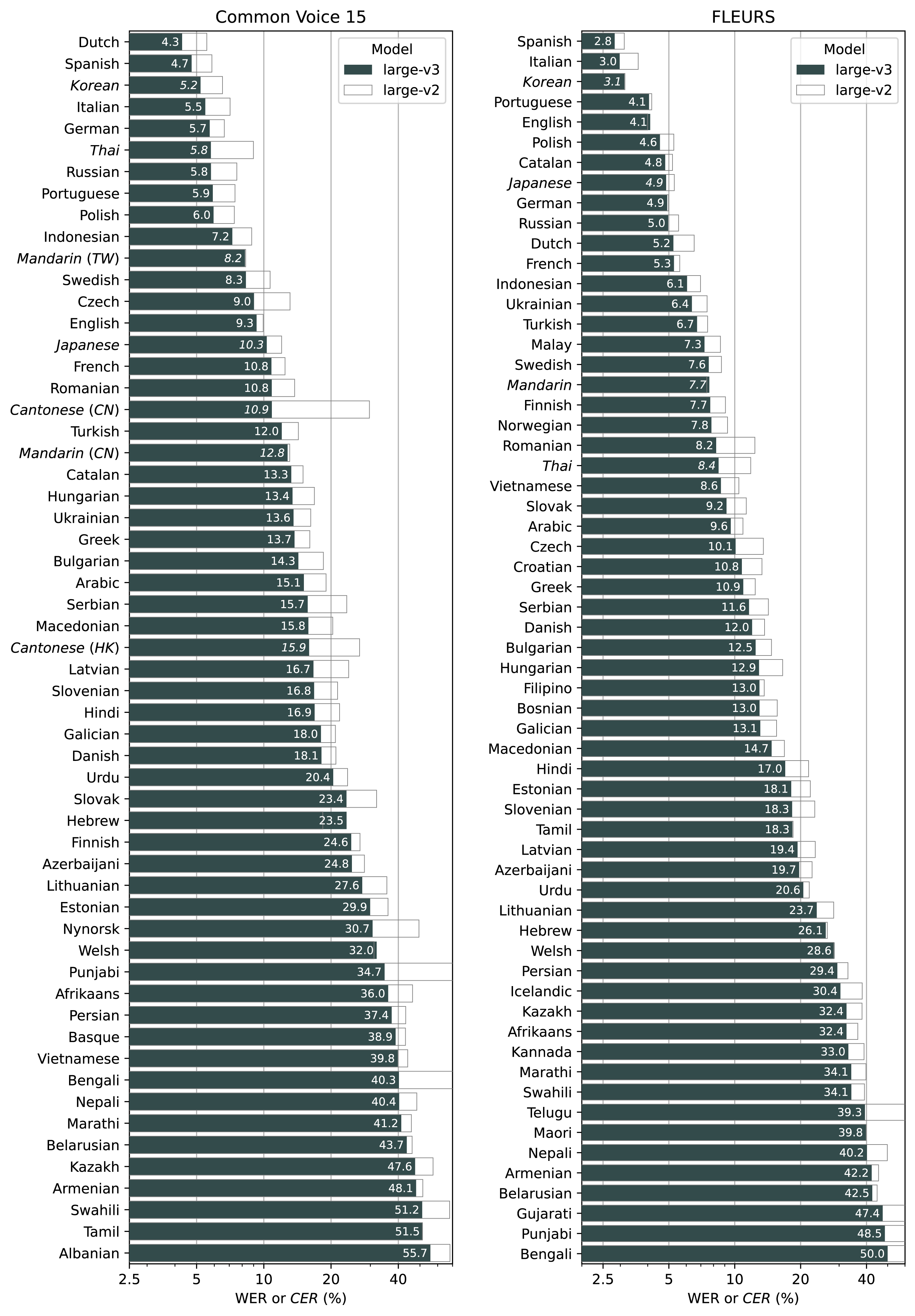
Language-breakdown
Languages evaluated using character error rates (CERs) instead of word error rates (WERs) are shown in Italic.
We used character error rates for Korean as well, in addition to the five languages that we used CERs in the paper (Chinese, Japanese, Thai, Lao, and Myanmar). While Korean does use spaces to separate words, there are many cases where it is acceptable to omit spaces between words, and we noticed that the labels in both Common Voice 15 and Fleurs have many instances of inconsistent or incorrect spacings.
In the Fleurs dataset, we used the transcription column which contains labels that are pre-processed and normalized from the raw_transcription column, with these two exceptions:
- Korean labels have many phrases inside parentheses that usually repeats the preceding word in the Latin script; we removed these using regular expressions.
- Serbian labels contain transcriptions in both Latin and Cyrillic scripts, and Whisper's predictions for Serbian also often fluctuate between the two scripts. For evaluation, we converted both the labels and the model predictions into Cyrillic and computed the word error rates.
This article comes from: https://github.com/openai/whisper/discussions/1762