 The applications of automatic speech recognition (ASR) systems are proliferating, in part due to re-cent significant quality improvements. However, as recent work indicates, even state-of-the-art speech recognition systems – some which deliver impressive benchmark results, struggle to generalize across use cases.
The applications of automatic speech recognition (ASR) systems are proliferating, in part due to re-cent significant quality improvements. However, as recent work indicates, even state-of-the-art speech recognition systems – some which deliver impressive benchmark results, struggle to generalize across use cases.
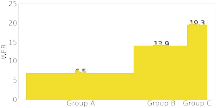
In this paper, we review relevant work, and, hoping to inform future benchmark development, outline a taxonomy of speech recognition use cases, proposed for the next generation of ASR benchmarks. We also survey work on metrics, in addition to the de facto standard Word Error Rate (WER) metric, and we introduce a versatile framework designed to describe interactions between linguistic variation and ASR performance metrics.
In the paper below, 4 engineers from Google, describe how they believe a better benchmark system for ASR can be made.
| Aksënova, Alëna & Esch, Daan & Flynn, James & Golik, Pavel. (2021). How Might We Create Better Benchmarks for Speech Recognition? Proceedings of the 1st Workshop on Benchmarking: Past, Present and Future, pages 22–34 August 5–6, 2021. ©2021 Association for Computational Linguistics https://aclanthology.org/2021.bppf-1.4.pdf |
or here
![]() How Might We Create Better Benchmarks for Speech Recognition?
How Might We Create Better Benchmarks for Speech Recognition?