Natural Language processing and Text Mining
While ‘Text Analytics’ is a more generic term, more specific terms that are current in computer science and linguistics are ‘Natural Language Processing’ and ‘Text Mining’. NLP or Natural Languages Processing is the umbrella term for the processing, exploration and analysis of data using computational linguistic tools and approaches. ‘Text mining’ is the process of converting unstructured or semi-structured oral and written data into structured data for exploration, analysis, and interpretation. Other methodologies involve statistical tools and machine learning. The scheme below illustrates the variety of focuses when applying computational methods to text.
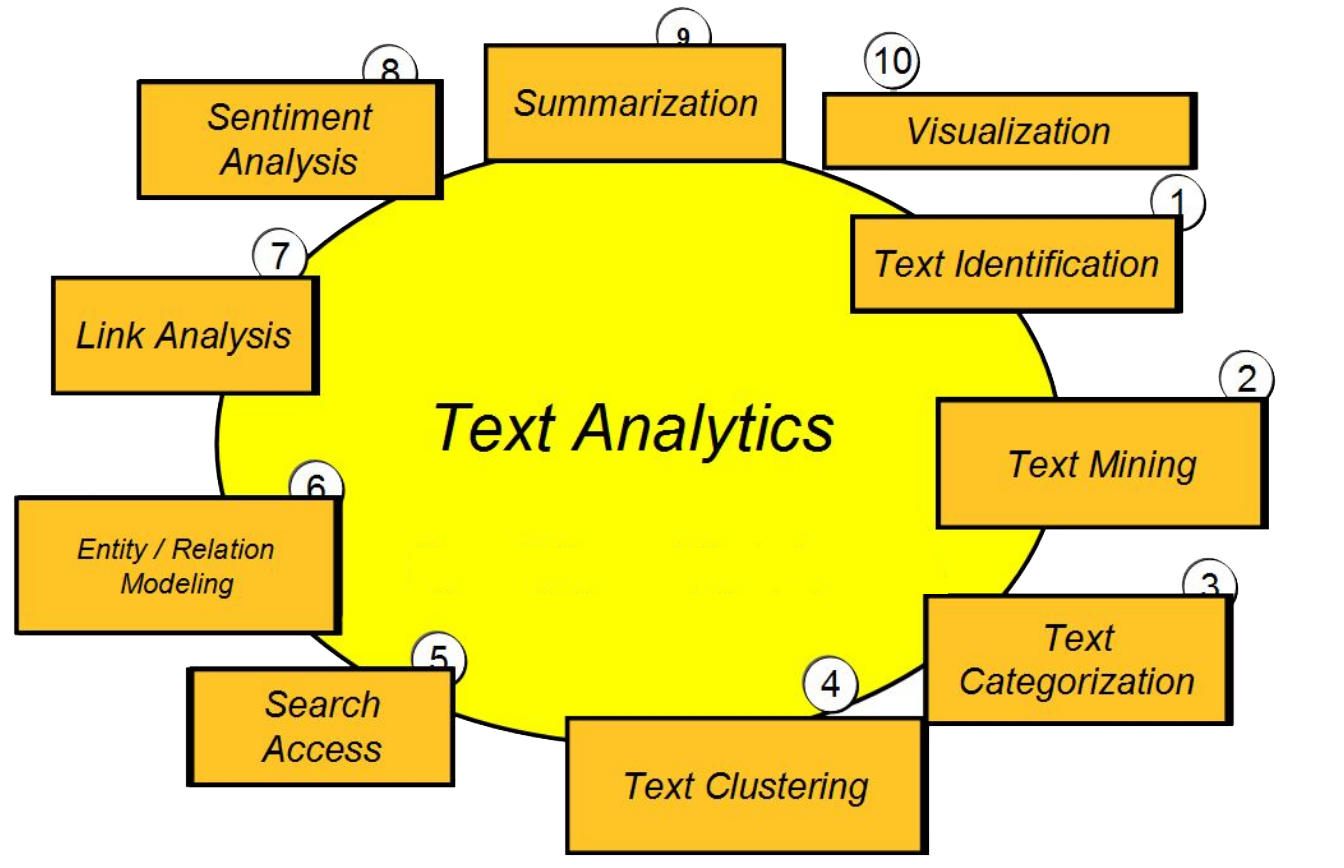
NLP tools that are commonly used to facilitate text processing and information extraction are spell checkers/correctors, tokenizers, stop word removers, stemmers, lemmatizers, POS-taggers, chunkers such as sentence splitters, syntactic parsers, thesauri and ontologies, keyword extractors.
Automated speech recognition (ASR) tools partially replace manual transcription. They can mark silences and recognize different speakers in, for example, an interview. An important surplus is that ASR converts spoken language into text which can be aligned with the spoken fragments. Emotion recognition detects positive and negative feelings, taking into account silences, tone/pitch and role-taking.
Named entity recognizers (NER) extract named entities, i.e. proper nouns such as person names, names of organisations, geographical terms, but also dates, percentage, numbers.
Other Information extraction (IE) tools detect keywords, generate frequency lists and summaries, produce word clouds, and categorise documents. There are also excellent tools for discovering (unexpected) patterns such as concordances (KWiC/Keywords in Context) and correlations.
Examples of NLP tools can be found here.
It speaks for itself that this technology has been developed with a strong focus on the characteristics of language expressed in written form. But now that technologies are increasingly capable of automatically turning speech into text, the next challenge will be to develop specific methodologies for the automatic analysis of spoken text. This is at the core of the discipline of language technology, but is still unexplored territory with regard to typical humanities data such as oral history interviews, or data that is used by media scholars such as television and radio broadcastings.