
As a follow up of the CLARIN workshop on Oral History (OH) archives in Oxford (April 2016), we have applied for funding to prepare two workshops: the first one in December 2016 in Utrecht and the second one in April 2017 in Arezzo. The proposal for these two workshops was granted in October 2016.
The envisaged outcome of the two workshops is an implementation plan for an OH transcription chain that can be integrated into the CLARIN infrastructure. Once the implementation plan is written, it will be submitted to CLARIN ERIC for funding.
The first workshop (6-7 December) in Utrecht is an "afternoon-evening-morning" workshop for a small amount of participants (<15).
Main goal of the workshop is to:
- sketch the working-together process for the following 3 to 4 months
- set-up a working environment (GoogleDocs?)
- appoint responsabilities
- find necessary colleagues/partners
- find possible (CLARIN) hosts for OH transcription services for the three languages
- design the "ideal transcription chain" for oral historians
- sketch the organisation of the second workshop: invitees and agenda
In the months after the December workshop the people who were present (and others) will write a proposal that will be discussed, improved and finalised at the second workshop in Arezzo.
Participants
At this moment (29 November) the following persons have confirmed their availability at the workshop.
| Name | Country | Affiliation | Expertise |
|
Silvia |
IT | Dipartimento di Scienze della formazione, scienze umane e della comunicazione interculturale | Linguistics |
| Riccardo del Gratta |
IT | ILC | Infrastructure |
| Stef Scagliola |
LU | Faculté des Lettres, des Sciences Humaines, des Arts et des Sciences de l'Education | Oral History |
| Martin Wynne |
UK | IT Services, Oxford Text Archive | |
| John Coleman | UK | Phonetics Laboratory | Phonetics |
| Henk van den Heuvel |
NL | CLST, Radboud University | Language and Speech Technology |
| Arjan van Hessen |
NL | HMI, University of Twente | Language and Speech Technology |
| Parttime Participants | |||
| Roeland Ordelman |
NL | Netherlands Institute of Sound and Vision | Language and Speech Technology |
| René van Horik |
NL | DANS | Infrastructures |
| Oana Inel |
NL | VUA | Computer Science |
| Leon Wessels |
NL | CLARIN-EU | Infrastructure |
| Willemien Sanders |
NL | CLARIN-EU | OH |
| Norah Karrouche |
NL | CLARIAH - WP5 | OH |
Location & Agenda
The workshop started 6 December at 12:30 and finished 7 December at 13:00.
The location of the meeting was the modern SURF-building in Utrecht. The SURF-building is (more or less) in the railway station. Walking from and to the trains to Amsterdam Airport is less than 10 minutes. Also the historical centre of Utrecht (Dom tower) is less than 10 minutes by foot.
Tuesday 6 December 2016
| Time | Activity | Moderator |
| 12:30 | Lunch | Arjan van Hessen |
| 13:30 | Intro: Goals of the project, goals of this workshop | Henk van den Heuvel |
| 13:50 | Oxford and beyond | Willemien Sanders |
| 14:10 |
Make inventory of relevant decisions for successful transcription chain
|
Arjan, All |
| 15:30 | Tea & Coffee | |
| 15:45 | Crowdsourcing issues: Crowdtruth | Oana Inel |
| 16:30 | Research data management and the role of the EUDAT CDI
|
René van Horik |
| 17:15 | (CLARIN) hosts for OH transcription services for the three languages
|
Roeland Ordelman |
| 18:00 | Sketch the working-together process for the following 3 to 4 months Set-up a working environment (GoogleDocs?) |
All |
| 19:00 | Dinner at Sir/Signore/Meneer Buscourr |
Wednesday 7 December
| Time | Activity | Moderator |
| 9:30 | Sketch the working-together process for the following 3 to 4 months (cont’d) Appoint responsibilities / actionpoint holders |
Henk, Arjan |
| 10:30 | Coffee & Tea | All |
| 10:45 | Design agenda for the Arezzo meeting | All |
| 11:30 | Set-up list of invitees for the Arezzo meeting (using the participants list of the meeting in Oxford) | All |
| 12:30 | Lunch | |
| 13:30 | Adjourn |
Blog report
A Short Report of the workshop "The Oral History Transcriptions Chain"
Pre-history
At a general CLARIN-Oral History workshop held in Oxford in April 2016, a number of conclusions could be drawn:
- There is a growing interest from different CLARIN member-countries to use modern Human Language Technology for opening up Oral History data in archives that has not been transcribed, and for speeding up the process of creating transcripts from one’s own interviews.
- An infrastructure containing both the tools to perform these tasks and storage to stimulate the reuse of the transcripts, that requires no extensive knowledge of ICT by its users, is very much desired.
- The accessibility of OH collections in the participating counties is widely divergent. Some have a national infrastructure with storage centres, and online catalogues with extensive metadata, on digitized content, others have vast amounts of OH collections but only in their original analogue format.
As digitalisation of analogue recordings is becoming increasingly easier, storage is affordable, and HLT performs well enough to be applied on data with speech that is clear and understandable, it was decided to explore the possibilities to create such an infrastructure.
The first call in CLARIN (EU) was used to propose two preparatory workshops one in Utrecht which was just held, and one in Arezzo in April 2017, that should lead to a concrete proposal for an infrastructure that facilitates the entire process of opening up of oral history data,: from digitisation to transcription, making use of automatic speech recognition as intermediary technology.
Targets in Utrecht
 The goal of the workshop in Utrecht was setting up a workflow and division of tasks to perform in the next four months, and that will be finalized in Arezzo, :
The goal of the workshop in Utrecht was setting up a workflow and division of tasks to perform in the next four months, and that will be finalized in Arezzo, :
- What are the tasks that have to be covered to create the proposal?
- Who will be responsible for the content of each part of the proposal ?
- Who are the co-authors of each topic?
- What infrastructure will be used to describe the topics (snap ik niet)
- Setting the deadlines for the tasks
- Envision the program for Arezzo, (who to invite, what kind of activities to organize)
- What should be the follow up of Arezzo?
Day 1
At the end of the morning of December 6th, the foreign guests from England (Martin Wynn) and Italy (Silvia Calamai & Riccardo del Gratta) arrived together with the Dutch participants (die ook noemen) at the SURF-offices in Utrecht. At 13:30 Henk van den Heuvel welcomed everybody, and explained the goals of the workshops and of the proposal to be realised in spring 2017.
After which, Willemien Sanders, currently involved in the follow-up of the Oxford-workshop on behalf of Clarin EU, gave a short overview of what action points had been formulated in achieved in Oxford.
This was followed by Henk van den Heuvel’s presentation of the envisioned time table, as shown below.
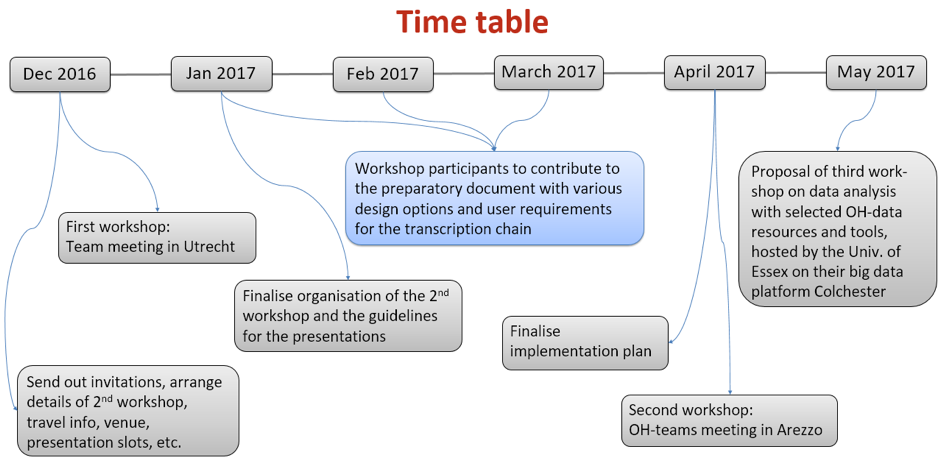 Time scheme for the period between the two workshops
Time scheme for the period between the two workshops
Table with workpackages and responsibles
The outcome of this discussion was that 8 tasks were formulated for the various building blocks of the envisaged transcription chain:
| Topic | Responsible | Co-writers |
| AD & DD conversion | Arjan | John |
| ASR | Henk | Louis ten Bosch, Arjan,Stef, Maurizio Omologo, Piero Cosi, Francesco Cutugno, Sergio Grau Puerto |
| Transcription correction | ||
| - General | Arjan | Stef |
| - Crowdsourcing | Oana | Arjan |
| Transcription Guidelines | Stef | Silvia, Louise |
| Alignment | John | Silvia, Arjan |
| Metadata | Stef | Dieter van Uytvanck (technical), Silvia (metadata selection) |
| Export | Tba | |
| Hosting |
NL: René UK: Martin IT: Riccardo |
NL: Roeland (NSIV, UTwente) UK: Thomas Hain (Sheffield), John (Computer Cluster, Oxford) IT: Silvia (Arezzo/Siena) |
| Overview of the task and the people working on them | ||
 After the coffee break three interesting presentations were held by:
After the coffee break three interesting presentations were held by:
- Rene van Horik (DANS) about potential data hosting via EUDat.
-
Oana Inel (VU) on the Crowdsourcing platform CrowdFlower. Oana showed us how easy it is to setup a Crowdsourcing environment where "other" people (you do not know them), can help you with the correction of transcriptions (made by humans or machines). A small example of a 1-minute audio segemnt and the accompanying transcription can be seen here (un/pw =
This email address is being protected from spambots. You need JavaScript enabled to view it. /crowdtruth). - Roeland Ordelman (NISV) who offered an overview of similar activities for a transctiption service as part of the WP5-workpackage of the infrastructure program CLARIAH
The first day was ended with a nice diner at the old "Mr. Buscourr"
Day 2
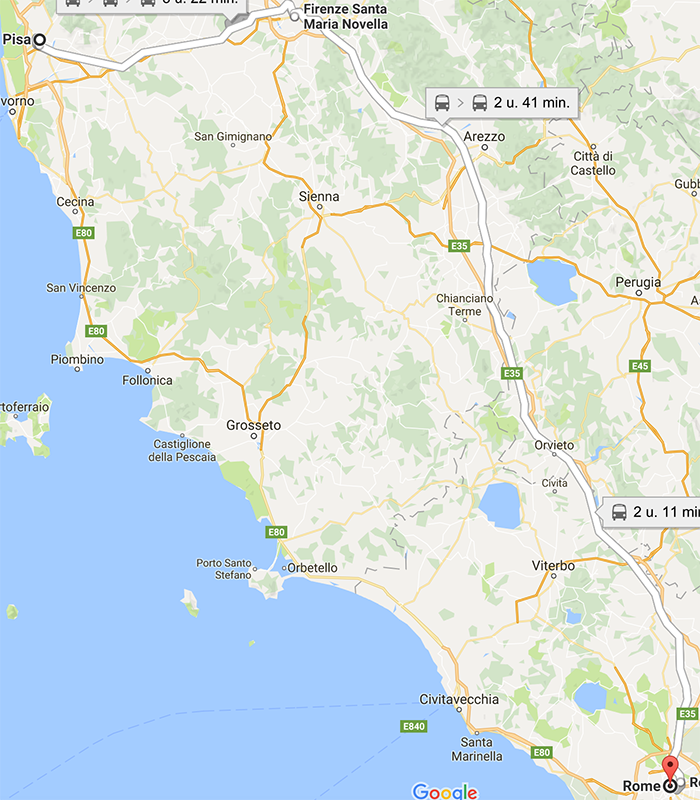 The second day was mainly focused on the organisation of the Arezzo-workshop: when, where, who, what?
The second day was mainly focused on the organisation of the Arezzo-workshop: when, where, who, what?
Because Arezzo does not has an airport, visitors need to fly to Pisa, Firenze or Rome and than take the train to Arezzo (additional 1 to 2½ hour extra travel time).
So starting early in the morning or ending at the end of the afternoon is a bit problematic without an additional night. Stef and Willemien have offered to “solve” this issue.
Further, the responsibilities of the participants in terms of document writing and implementation of tasks were verified and settled.
At 12:30 this short, but very effective workshop was concluded and participants left with a list of tasks to perform in the coming 4 months ?.
Arjan & Henk