The main goal of this website is to give an overview of technology that can be used in the processing of Spoken Content data in general: from an analogue tape and perhaps a handwritten summary to a digital recording including digital transcripts, speaker allocation/recognition (who is speaking when), emotion-markers, speech velocity and much more.
One may think of technologies working on the primary data (the spoken content) such as ADC (Analogue-Digital Conversion), ASR (Automatic Speech Recognition) that can be used to automatically generate transcripts of the spoken content, OCR (Optical Character Recognition) that can be used to digitize (handwritten or typed) transcripts on paper, Audio-Video converters that can be used to convert the recordings from a less suitable digital format into a more common one, or Speaker Diarization & Speaker Recognition (deciding who is talking when).
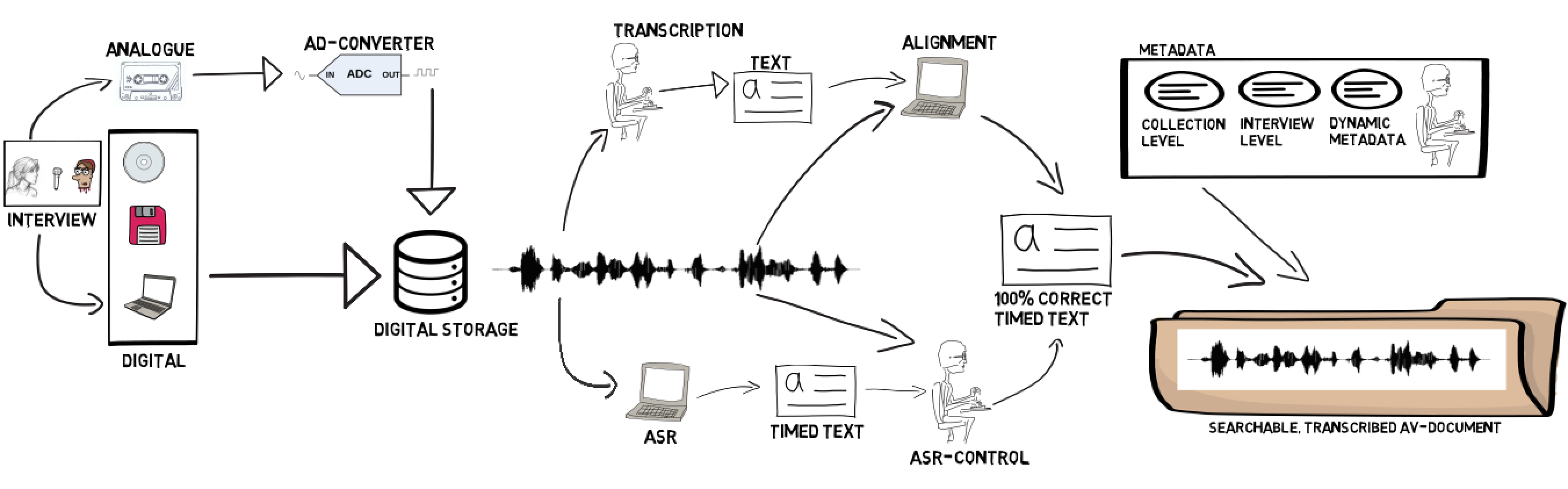 But software tools can also be used to work on those digital transcripts and related metadata. One may think of LIWC (Linguistic Inquiry & Word Count, a computerized text analysis program that is considered as a gold standard) or Emotion Detection where both the spoken words and the tone-of-voice are used to “calculate” the emotion of the speaker(s).
But software tools can also be used to work on those digital transcripts and related metadata. One may think of LIWC (Linguistic Inquiry & Word Count, a computerized text analysis program that is considered as a gold standard) or Emotion Detection where both the spoken words and the tone-of-voice are used to “calculate” the emotion of the speaker(s).
All these technologies can be used for different disciplines of Spoken Content. However, on this website we will sometimes focus on Oral History recordings: recordings of mostly one interviewer and one interviewee about a special event in the past or someone's life during a now closed period.
The setup of this website is as follows:
- an overview and explanation of the technologies that are often used for editing and processing OH recordings,
- an overview of existing software that, using the technologies described, can be used for the processes of OH data
- a number of tutorials that explain how to take certain steps, what to pay attention to and how to avoid the known pitfalls.