 At the end of March, we got the first version of our paper back to the LREC-COLING workshop about Holocaust Testimonies as Language Resources (Workshops – LREC-Coling 2024). We needed to modify some (minor) issues and started to do so. The paper is about the arrival of Whisper (autumn 2022) and related packages, which allow you to do better, richer and faster speech recognition. Whisper was already a kind of miracle a year ago, but certainly since the "related packages" have come of age, it is only getting much better.
At the end of March, we got the first version of our paper back to the LREC-COLING workshop about Holocaust Testimonies as Language Resources (Workshops – LREC-Coling 2024). We needed to modify some (minor) issues and started to do so. The paper is about the arrival of Whisper (autumn 2022) and related packages, which allow you to do better, richer and faster speech recognition. Whisper was already a kind of miracle a year ago, but certainly since the "related packages" have come of age, it is only getting much better.
One of the reviewers noted that in the listing of standalone ASR-software, he missed a new programme from Graz in Austria: aTrain. Immediately we search on the internet to figure out what aTrain was. It is a Whisper-using software package for ASR and it is available for free via a download at the Microsoft shop.
Downloaded, installed and ran! And yes: again a joy to use.
For Apple, there has been MacWhisper for a while: a standalone package that allows you to run Whisper on a modern MacOS computer. For Windows, you could use SubtitleEdit, but this software is much more than a "simple" speech recogniser (however: it works fine).
And now there is aTrain: a software package similar to MacWhisper that runs on Windows and Linux.
The difference with MacWhisper is that aTrain uses more of Whisper's modern variants/add-ons. MacWhisper is a CPP implementation of the classic Whisper like OpenAI provided 1.5 years ago. But aTrain is newer and can do e.g. diarization, and is much faster than the original Whisper.
After downloading aTrain, the software asks if you want to install it. Choose yes and wait some 10 min, then you'll have the modern speech recogniser available.
Description
aTrain is an self-installing and encapsulated tool for automatically transcribing speech recordings utilizing state-of-the-art machine learning models without uploading any data. It was developed by researchers at the Business Analytics and Data Science-Center at the University of Graz and tested by researchers from the Know-Center Graz.
| Haberl, A., Fleiß, J., Kowald, D., & Thalmann, S. (2024). Take the aTrain. Introducing an interface for the Accessible Transcription of Interviews. Journal of Behavioral and Experimental Finance, 41, 100891. |
aTrain was developed by researchers at the Business Analytics and Data Science-Center of the University of Gräz and tested by researchers at the Know-Center Graz.

What is offered
aTrain offers the following benefits:
Fast and accurate
aTrain provides a user friendly access to the faster-whisper implementation of OpenAI’s Whisper model, ensuring best in class transcription quality paired with higher speeds on your local computer. Transcription when selecting the highest-quality model takes only around three times the audio length on current mobile CPUs typically found in middle-class business notebooks (e.g., Core i5 12th Gen, Ryzen Series 6000).
Speaker detection
aTrain has a speaker detection mode and can analyze each text segment to determine which speaker it belongs to.
Privacy Preservation and GDPR compliance
aTrain processes the provided speech recordings completely offline on your own device and does not send recordings or transcriptions to the internet. This helps researchers to maintain data privacy requirements arising from ethical guidelines or to comply with legal requirements such as the GDRP.
Multi-language support
aTrain can process speech recordings in more or less 57 languages.
MAXQDA and ATLAS.ti compatible output
aTrain provides transcription files that are seamlessly importable into the most popular tools for qualitative analysis, ATLAS.ti and MAXQDA. This allows you to directly play audio for the corresponding text segment by clicking on its timestamp.
NVIDIA GPU support
aTrain can either run on the CPU or an NVIDIA GPU (CUDA toolkit installation required). A CUDA-enabled NVIDIA GPU significantly improves the speed of transcriptions and speaker detection, reducing transcription time to 20% of audio length on current entry-level gaming notebooks.
Running aTrain
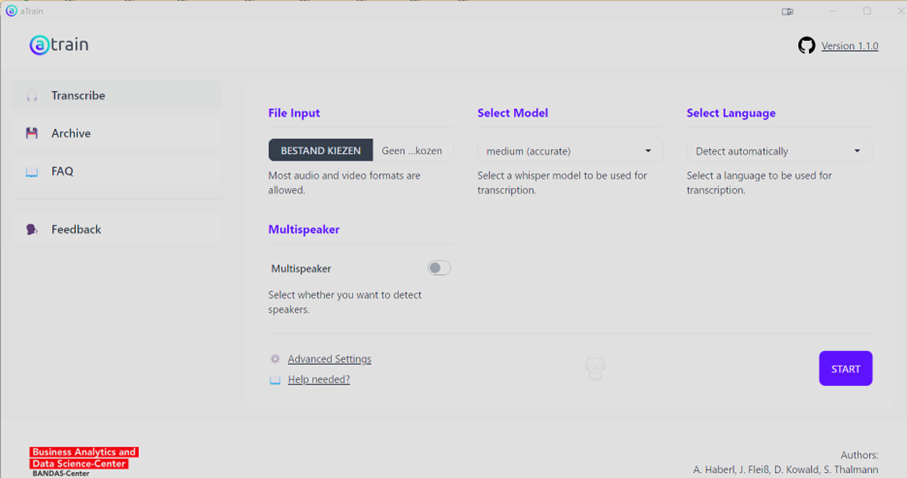
To run aTrain, you choose an AV file (video or audio), select the OpenAI-model to use (tiny - large), choose the language spoken or leave it blank so the software will detect it, and possibly indicate whether you want to recognise speakers. If so, you need to add the amount of different speakers in the recording.
Finally you click start and wait a while. On my PC (i9, Nvidia card), this takes a little less than 20% of the duration of the recording. The results are saved in a special directory.
That output contains the following files:
| metadata.txt | recognition metadata (language, model, audio duration, etc.) |
| transcription.json | a complete result of the recognition |
| transcription.srt | the standard subtitles |
| transcription.txt | the recognised text with the selected speakers |
| transcription_timespans.txt | the same but with the start times of each segment |
| transcription_maxqda.txt | the version that can be read in MaxQDA |
Conclusion
aTrain works very well and can be used by anyone on their own modern Windows machine. The use of GPU however, is helping a lot in improving the velocity of the recording! The addition of diarization (speaker detection) makes it a better choice than MacWhisper (for now).
Download
![]() aTrain can be downloaded (>10GB) in the Microsoft store: https://apps.microsoft.com/detail/9n15q44szns2
aTrain can be downloaded (>10GB) in the Microsoft store: https://apps.microsoft.com/detail/9n15q44szns2