ORAL HISTORY:
USERS AND THEIR SCHOLARLY PRACTICES IN A MULTIDISCIPLINARY WORLD
 Main building of the Ludwig-Maximilians-University at Geschwister-Scholl-Platz in Maxvorstadt, München
Main building of the Ludwig-Maximilians-University at Geschwister-Scholl-Platz in Maxvorstadt, München
Over the past 2 years a number of researchers from various backgrounds have been working on the exploitation of digital techniques and tools for working with oral history (OH) data. These endeavours have been supported by CLARIN (Common Language Resources and Technology Infrastructure) as this European infrastructure for harmonizing and sharing data and tools for linguists, aims at broadening its audience, for example, to the social science community. It intends to realize this objective by reaching out to scholars who are interested in cross disciplinary approaches and who work with interviews/oral histories/qualitative data.
CLARIN is interested in how it can better support the diversity of practices among social scientists, oral historians and digital humanists. and how it can lower barriers to the use and take up of its resource and technologies. Through supporting workshops they can get researcher-oriented feedback and suggestions for refinement and improvement of its resources.
The third of our programme of workshops, supported by the funding program, CLARIN will be held in Munich, Germany on 19-21 September 2018, and will focus on the analysis phase of the research process. This builds on the work already done during previous workshops, in order to create automatically generated transcripts. By bringing together CLARIN technologies for speech retrieval and alignment from different countries, the ‘Transcription Chain’ has been developed, a prototype that will also be tested during the workshop.
The invitation-only workshop aims to gather of evidence on scholars' everyday practices when working with OH data. By documenting and comparing these engrained practices, and by venturing into different approaches and methods to their data, namely by using unfamiliar annotation. For the purpose of this workshop we have agreed to work with audiovisual and textual data in 4 languages: Dutch, English, German and Italian, and will have prepared some materials for participants to work with, in language groups.
There will be some preparatory work that has to be done prior to the workshop that will consist of completing a matrix of user approaches and tools for your specialty, analysing some extracts of data and reviewing some documentation that we will send in advance. Our estimate is that this will take somewhere between 5 and 10 hours of your time and the 'homework' aims to reflect participants' various expertise that will be used in the workshop.
No specific technical knowledge is required.
All participants need to be able to commit to the full 3 days - Wednesday lunchtime on 19th September to lunchtime on Friday 21st September. We are able to pay up to €275 maximum towards your economy class travel. Please ensure that your travel is booked well in advance and check with us in advance if you need to. Hotels and meals will be provided from Wednesday lunchtime to Friday lunch. We may be able to arrange pick-ups from airports if people's travel plans coincide.
Programme
Below the workshop-program. of the workshop.
Agenda München 2018
Wednesday 19 September
Overview and demos
| Morning | Travel time |
| 14:00 - 14:15 | Welcome and overview of the workshop
|
| 14:15 - 15.30 | Very brief summary of landscape(s)
|
| 15.30 - 16.00 | Coffee |
| 16.00 - 18.00 | Demonstration of the TChain workflow Christoph Draxler and Arjan van Hessen Introduction to the workshop sessions/resources Louise and Maureen Expected outcomes and evaluation method St the workshop Norah and Max Broekhuizen Introductions in language groups |
| 19:30 | Dinner |
Thursday 20 September
Information exchange: envisaging and embracing others’ techniques and tools
| 9:15 - 9:30 | Assemble into language groups |
| 9.30 - 11.00 | Session 1: The Transcription Chain (TChain) (hands on) Arjan and Christoph
|
| 11.00 - 11.30 | Coffee |
| 11.30 - 13.00 | Session 2: Researcher annotation tools (hands on) Liliana Melgar and Silvana di Gregorio
|
| 13:00 - 14:00 | Lunch |
| 14:00-15.45 | Continue Session 2 Researcher annotation tools Liliana Melgar and Silvana di Gregorio
|
| 15.45 - 16.15 | Coffee |
| 16.15 - 18.00 | Session 3: On the fly linguistic tools (hands on) Jeannine Beeken
|
| 19:30 | Dinner |
Friday 21 September
Information exchange: envisaging and embracing others’ techniques and tools
| 9:00 - 11.00 |
Session 4: Preprocessing and textometry tools (hands on) Florentina
|
| 11:00 - 11:15 | Coffee |
| 11.15 - 13.15 | Session 5: Emotion recognition tools: audio and video Khiet Truong
|
| 13:15 - 13:30 | Short summary and adjourn |
| 13.30- 14.00 | optional lunch |
Presentation
The link below gives access to the presentations of the workshop.
Blogs
Two blogs were written shortly after the workshop by Stef Scagliola and Arjan van Hessen.
At the CLARIN-days in October (Pisa, Italy) a poster was presented.
In december 2018, three papers and a workshop were submitted for the DH2019 conference in Utrecht. unfortunately, two papers were rejected
Evaluation of the OH portal (Arjan van Hessen)
Oral History under scrutiny in München (Stef Scagliola & Louise Corti)
Oral History under scrutiny in München
Cross disciplinary overtures between linguists, historians and social scientists
Stef Scagliola, Louise Corti.
Heading to München at the end September offers the spectacle of cheerful Germans wearing dirndls and lederhosen, celebrating their Oktoberfest with remarkable patriotism and tons of good beer. This year, the Bavarian stronghold hosted another cheerful gathering of a dedicated community: a CLARIN multidisciplinary workshop in which scholars in the fields of speech technology, social sciences, human computer interaction, oral history and linguistics engaged with each others’ methods and digital tools. The idea is that as the use of language and speech is a common practice in all these scholarly fields, the use of a digital tool that is already mainstream in a parallel discipline, could open up new perspectives and approaches for searching, finding, selecting, processing and interpreting data.
This was the fourth workshop supported by CLARIN ERIC, a European Research Infrastructure Consortium for Language Resources and Technology, offering a digital infrastructure that gives access to text and speech corpora and language technology tools for humanity scholars. One of CLARIN’s objectives is to reach out to social science and humanities scholars in order to assess how the CLARIN assets can be taken up by other disciplines than (computational) linguistics and language technology.
At the first two workshops in Oxford (2016) and Utrecht (2016), we assessed what the potential could be of bringing together state of the art speech technology, descriptive and analytical tools for linguistic analysis and oral history data, to open up massive amounts of interview data and analyse them in new, often unexpected ways. Also the website oralhistory.eu was set up to cross-disciplinary communicate work from this group. In Arezzo in 2017, the first challenge was taken up, applying speech recognition software to Italian, German, Dutch and English oral history data and evaluating the experiences of scholars. The reasons why CLARIN can make a difference in the world of oral history is explained in a series of short multilingual videoclips with speech technologist Henk van de Heuvel, linguist Silvia Calamai, and data curator Louise Corti.
Arezzo yielded a roadmap for the development of a Transcription Chain (T-Chain), in which various open source tools are combined to support transcription and alignment of audio and text in various languages. In München we had the opportunity for ‘the proof of the pudding’, testing the prototype of the T-Chain, known as the OH Portal, with data that had been pre-selected and prepared by the workshop organisers and sessions leaders.
In our München workshop, we devoted 2 days to experimenting with 5 tools, building on the homework the participants were asked to do, i.e. install software and become familiar with it. The tools ranged from annotation of digital sources (ELAN and NVivo) to linguistic identification and information extraction. These were applied to text and audio-visual sources, with the intent of detecting language and speech features by looking at concordances and correlations, processing syntactic tree structures, searching for named entities, and applying emotion recognition (VOYANT, Stanford NLPCore, TXM and Praat). Some participants struggled to download software which suggested a lack of basic technical proficiency. This could turn out to be a significant barrier to the use of open source tools, as many of them require a bit more familiarity with, say, laptop operating systems. It was useful to have language technologists sitting amongst the scholars, witnessing first-hand some of the really basic challenges in getting started..
Sessions were conducted in four language groups (Dutch, English, German and Italian) and comprised 5-6 people (linguists, oral historians, social scientists and digital humanities scholars); a formal group evaluation followed each session. Their feedback suggested an overall positive experience. However, some of the approaches, for example, language features identified through concordances, such as use of particular and co-occurrent words and multi-word expressions in an interview, were very new to some of the scholars. Due to unfamiliar terminology and the unknown/unusual methodology of linguistic research, some people initially really struggled to comprehend how they worked and what their purpose was. However, we also witnessed some pleasing ‘Eureka’ moments and ‘Aha-Erlebnisse’ where scholars appreciated how (much) such analytic tools might help complement their own approaches to working with OH data, enabling them to elucidate features of spoken language, in addition to content.
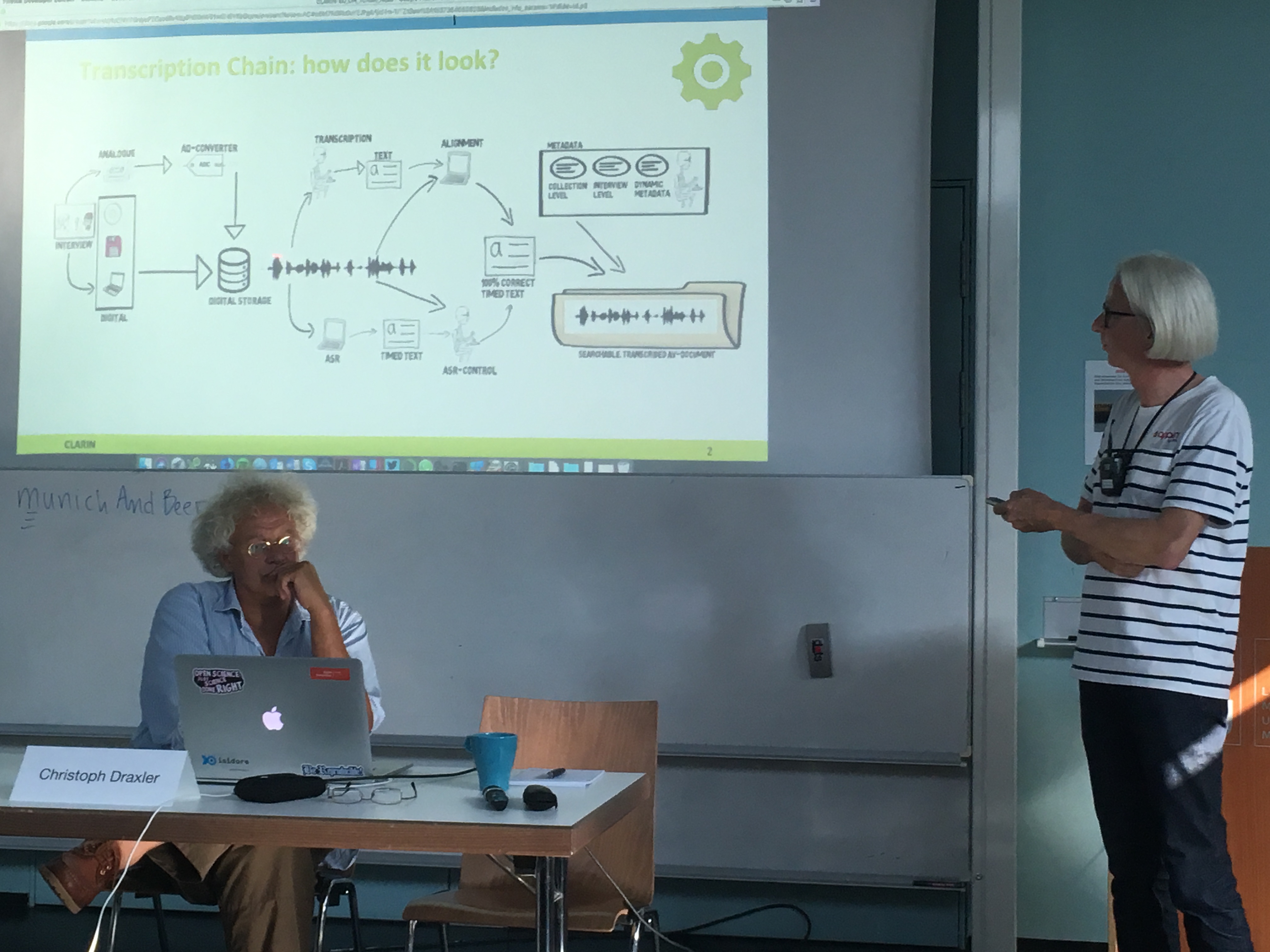 Christoph and Arjan present the T-Chain
Christoph and Arjan present the T-Chain
Transcription Chain
In Arezzo, one key takeaway message was to keep on developing the OH portal, and to keep it as simple as possible by making no or just a few demands on the audio input, having clear instructions and using as little technical jargon as possible. In autumn 2017, the team of Christoph Draxler at the LMU in München started to build the first version of the OH portal. Version 1.0.0 of the portal was presented to participants of the September 2018 workshop in München.
The overall assessment was that the portal met what was required: it is easy to use, the different steps are clear and the final results/outputs are easy to download.
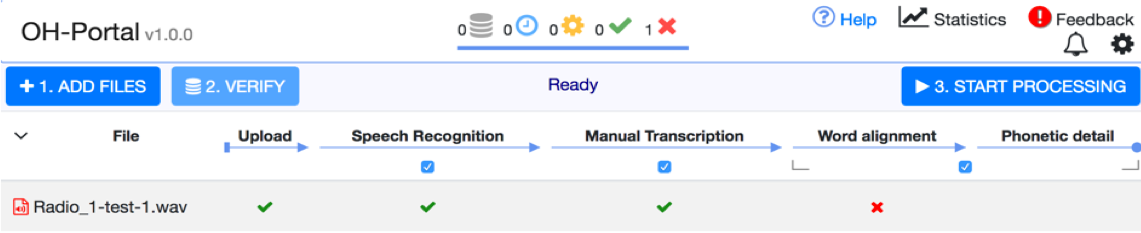 Screenshot of the OH portal
Screenshot of the OH portal
Hiccups: Scalability and Conversion
The biggest problem encountered in the München workshop was the scalability: the computers of the LMU could not handle 25 simultaneous requests to process an audio-file. The problem was solved overnight by the team of Christoph, but scalability is certainly something to work on in the next version. Moreover, it also would be very welcomed if the portal could give the users an estimation of the waiting time, or the certainty that the T-Chain is actually processing the request, and is not stuck because of an error or a crash. It is this uncertainty that can strongly discourage the uptake of such technology. Another issue that was a challenge to the participants, was extracting the audio from video interviews, which are increasingly becoming mainstream, and/ or converting the huge variety of formats (e.g. *.wma or *.mp3) into the prescribed *.wav format. For the time being this the only format that is supported by the T-Chain. See for a detailed blog by Arjan van Hessen and Christoph Draxler on the evaluation of the OH Portal in München.
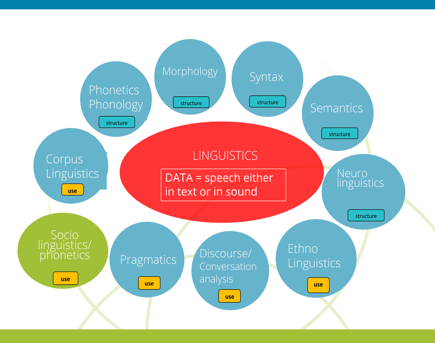
Landscape of disciplines
During the workshop’s introduction, participants from a variety of disciplines provided insights into how oral histories are approached and analysed in their respective disciplines. Perhaps not surprisingly, every discipline consists of distinct sub-disciplines that use different approaches and often refute the usefulness of, or are ignorant about, each other’s methods and tools. In fact, talking about ‘linguistics’ is a simplification, just as the term ‘oral history’ is an aggregation of a huge variety of approaches to interpreting interviews on people’s personal past. For instance, whereas most oral historians will approach an oral history interview as an intersubjective account of a past experience, some historians might wish to approach the same source as a factual testimony of an event. A social scientist may want to compare differences in recounting the past across the study’s interviewees. These approaches represent distinct analytical frameworks and may require different analytic tools. To illustrate this variety of landscapes within even one single discipline, we had invited, in advance, workshop participants to provide a couple of typical ‘research trajectories’ that reflected their own approach(es) to working with oral history data. A high-level simplified journey of an oral historian’s work with data looks something like this:
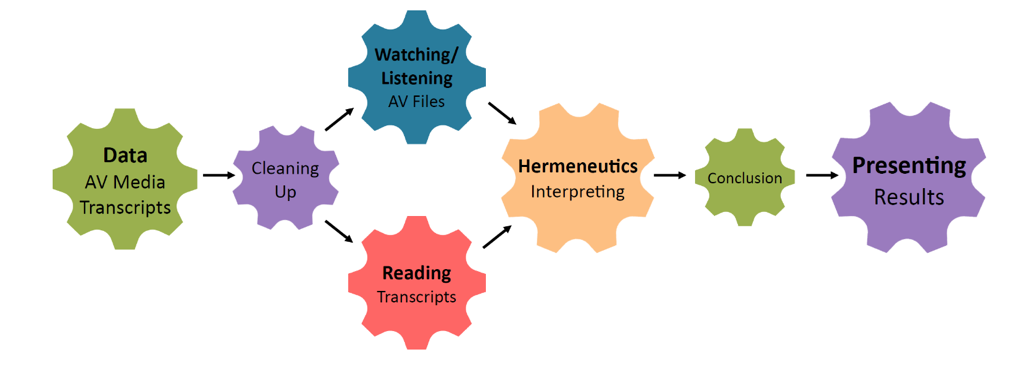 High-level simplified journey of an oral historian’s work with data (see here for the poster)
High-level simplified journey of an oral historian’s work with data (see here for the poster)
During the workshop, leaders of the four sessions covering data annotation, analysis and interpretation, were also invited to provide a brief sketch and characterization of the different approaches: a parade of disciplinary landscapes.
 Stef and Silvia explain what sociolinguists could do with spoken corpora. These yielded many insights into how specific practices are the same, yet have been assigned different names over time, or how the same term may signify different aspects in a different discipline. For instance, social scientific and historical approaches are actually quite similar, but reflection on analytic frameworks (i.e. content analysis, discourse analysis, narrative analysis) is rather weak in the oral historians’ methodologies, where oral history is first and foremost seen as an interviewing method. With these disciplinary overviews and insights in mind, we set out to explore whether or not the same annotation, linguistic and emotion recognition tools can cater to the needs of historians, social scientists and linguists in the same way. Examples of their typical work flows are shown below, and see their joint Presentation (CLARIN-OH_Munich18_Session0_Introduction.pdf)
Stef and Silvia explain what sociolinguists could do with spoken corpora. These yielded many insights into how specific practices are the same, yet have been assigned different names over time, or how the same term may signify different aspects in a different discipline. For instance, social scientific and historical approaches are actually quite similar, but reflection on analytic frameworks (i.e. content analysis, discourse analysis, narrative analysis) is rather weak in the oral historians’ methodologies, where oral history is first and foremost seen as an interviewing method. With these disciplinary overviews and insights in mind, we set out to explore whether or not the same annotation, linguistic and emotion recognition tools can cater to the needs of historians, social scientists and linguists in the same way. Examples of their typical work flows are shown below, and see their joint Presentation (CLARIN-OH_Munich18_Session0_Introduction.pdf)
 |
 |
 |
| Three screenshots of xxxx | ||
Researcher Annotation Tools
Annotation tools are familiar to linguists, oral historians and social scientists alike, but the way these tools are used and the terminology to describe what is being done varies considerably. Participants were given the opportunity to work with two different annotation tools: NVivo, a proprietary software designed with social scientists in mind, and ELAN, an open source tool favoured by linguists. While the two tools had a similar concept and objective, the vastly different terminology and user interface meant that users had to spend additional time acquainting themselves to the tool’s unique layout before being able to annotate.
![]() NVivo allowed participants to upload and group (code) data sources and mark-up text and images with “nodes” and memos. This tool worked particularly well with written transcripts, and allowed users to visually see mark-up and notes in the context of a transcript. Being able to collate all documents related to a single research project proved to be a clear benefit of the tool, with one user commenting that ELAN had a much more visual display and worked solely with audio and video data sources.
NVivo allowed participants to upload and group (code) data sources and mark-up text and images with “nodes” and memos. This tool worked particularly well with written transcripts, and allowed users to visually see mark-up and notes in the context of a transcript. Being able to collate all documents related to a single research project proved to be a clear benefit of the tool, with one user commenting that ELAN had a much more visual display and worked solely with audio and video data sources.
 ELAN allowed users to create “tiers” of annotation, differentiating types of tiers and specifying “parent tiers”. The ability to annotate the audio allowed users to engage with all aspects of an oral history interview from as early as the point of recording the data. Overall, the familiarity of annotation across disciplines made these tools more accessible to participants and allowed for easy cross-discipline collaboration. However, participants were reluctant to take the time to learn a new controlled vocabulary for each tool, and were unlikely to vary and be distracted from the tools they already knew. While the learning curve for annotation tools isn’t steep, CLARIN tools could be developed to ensure a uniformity of language and terminology for features, so the unique way of annotating within each tool becomes the focus, rather than a wholly unfamiliar terminology.
ELAN allowed users to create “tiers” of annotation, differentiating types of tiers and specifying “parent tiers”. The ability to annotate the audio allowed users to engage with all aspects of an oral history interview from as early as the point of recording the data. Overall, the familiarity of annotation across disciplines made these tools more accessible to participants and allowed for easy cross-discipline collaboration. However, participants were reluctant to take the time to learn a new controlled vocabulary for each tool, and were unlikely to vary and be distracted from the tools they already knew. While the learning curve for annotation tools isn’t steep, CLARIN tools could be developed to ensure a uniformity of language and terminology for features, so the unique way of annotating within each tool becomes the focus, rather than a wholly unfamiliar terminology.
A user quote on ELAN, “I would use this for an exploratory analysis of my oral history data.”
A user quote on NVivo: “It makes such a difference to be able to analyze all of your transcripts and AV-data in one single environment.”
On-the-fly linguistic tools (no pre-processing)
After a short introduction to different types of linguistic tools, for example lemmatizers, syntactic parsers, named entity recognizers, auto-summarizers, tools for detecting concordances/n-grams and semantic correlations, the open source online tools Voyant and Stanford CoreNLP were used to give an illustration of their possible uses within the research area of oral histories and social sciences.
Whereas the introduction was very much welcomed to gain insight in the generic linguistic tools and their shortcomings/opportunities, the free tools were met with some varied reactions. While many saw the advantages of using linguistic features, the limited functionality of such free tools was a barrier to their use. An example is limiting the amount of text than can be analysed. If the opportunities for use of these tools by non-linguists can be better defined, then CLARIN tools can be developed to meet these more basic needs.
Sociolinguists may take advantages from the use of Voyant: word frequency analysis may be rather interesting in oral history data, observed with the lenses of a sociolinguist. Although word frequency appears to be a rather controversial topic in linguistics, it is widely accepted that frequent words may influence phonetic change, and, secondly, frequent words may act as ‘locus of style’ for a given speaker. At the same time, it seemed that Voyant was not sophisticated enough to process uncleaned transcriptions.
A user quote on Voyant “I’d like the tool to be more transparent about how it generates a word cloud.”
Linguistic tools with pre-processing
The range of tools for supporting the identification and mark-up of linguistic features vary in their complexity and ease of use. The learning curve for those unfamiliar with the technique was found to be very high. TXM is an example of a ‘textometry’ tool that requires cleaned and partially processed data, necessitating some input before it can be used; much the same as many other tools that require structured input, such as XML. For using TXM, speakers need to be split, and noncompliant signs and symbols taken out, so that more accurate results can be gained. In the case of the 10 interviews about ‘Black Immigrants’ coming to the UK from the Caribbean from 1950-70s, the outcomes from TXM offer insights through features that can help with identifying specific features of the interview process such as: the relation between words expressed by interviewer and interviewee, the difference in active and passive use of verbs between gender, age or profession, or the specificity of certain words for a respondent. However, the methodological challenge is how to translate these insights into the paradigm the oral historian usually uses: how does this person attribute meaning to his or her past? In some ways, this might require the scholar to move away from the specific individual features in the creation of meaning – what is this person trying to tell me – to observing features that point to patterns in a corpus – of all the interviews this vocabulary seems to stands out. This requires a widening of methodological perspective in data analysis.
User quote on TXM “A bit of a struggle at first, but this helps you to do a close reading of an interview, and I think it fits perfectly within my traditional hermeneutical approach”

Emotion recognition tools
One of the most surprising dimensions of analysing a dialogue between interviewer and interviewee, was offered by Computer Scientist, Khiet Truong, who demonstrated how computer scientists measure emotions.
She started off with a simple cartoon. Our immediate observation varied; are they singing, arguing, or laughing? It is easy to make assumptions, yet these can seriously colour our interpretation. In a similar way, when we read an oral history, but do not listen to it, we are missing out on emotions that may underpin the conversation.
Indeed, a social signal (or emotion) can be a complex installation of behavioural cues. Studying social sign processing opens up the option of re-interpreting an interview, by reflecting on the function of the silence, or tone and whether they occur as a generic or a specific feature of communication within a corpus /collection of interviews. Once again, the tool, Praat has a high learning curve for those unfamiliar with speech technology and linguistics.
Summary
The introduction to disciplinary approaches and their analytic tools, plus the hands-on tools’ sessions were welcomed by participants. While the oral historians and social scientists saw some possibilities in using linguistic features, both the limited functionality of the free easy-to-use tools and the complexity and jargon-laden nature of the dedicated downloadable (and sometimes technologically challenging) tools were both seen as significant barriers to use; certainly in everyday research practice. This caused some frustration. Even in the process of selecting tools to be showcased and tested for the workshop, we, as organizers, encountered significant barriers in their selection. Many of the tools on the CLARIN site were not suitable for introduction due to their explicit lack of information on: their state of development; technical skills needed to download them; and even what they are for, explained in lay terms. We had to do a lot of work in preparing an additional simplified ‘layer of information’ on top of tools to make a hands-on workshop session.
This opens up a challenge for the CLARIN community for expanding the reach of the tools:
If we want CLARIN tools used by more disciplines, for example, those that work with oral history data, how can we dejargonise and break down some of these barriers to encourage new users? And, how can we present user-friendly tools that do not require a technologist to help install them?
If the opportunities for use of these tools by non-linguists can be better defined, then CLARIN tools can be both developed and explained to meet these more introductory needs. A new simplified ‘layer of information’ would be beneficial for tools. What does the tool do? What are key features? What are the input requirements (XML etc.); How does one access them and what are any technical requirements (Windows, Mac, Linux, versions of operating systems and browsers supported), links to simple documentation, and in what state of development they are? (A software maturity approach might be useful here). Once a user becomes ‘converted’ then they move into the realms of being a regular user!
Why not offer short and inspiring use cases of oral history processed with CLARIN tools?
The final point to make concerns ‘data’. We need sources that are well-documented and have rich-enough metadata. We also need to put in place a legal framework for processing data, so that options for conditions are clearly stated, and documented, and a user will know what will happen to a source once it is uploaded (deleted and so on). We propose that the CLARIN and CESSDA legal groups could work towards a standard GDPR-compliant agreement for use of tools that work with (potentially) personal data.
 The participants
The participants
We are delighted about the positive energy created during the workshop and note the value of the coming together of a multi-disciplinary team of workshop organisers, who had to step out of their own disciplinary comfort zones to design and run a workshop. This was not a quick process and it took months of meeting weekly to define and finalise this successful event. We really want to keep alive this momentum and rich dynamic for our Technology and Tools for Oral History initiative. We have a poster at the Bazaar at the forthcoming Pisa 2018 CLARIN Conference, and a number of meetings and training events will follow where a linguistic approach and language technology tools are introduced to social science, social history and oral history scholars. The workshop feedback was excellent, and we look forward to a further blog that uncovers user experiences and perceptions based on evaluation of the workshop.
Some final quotes from participants
On interdisciplinarity: ‘I have listened to some of the recordings, I have read your article, I know what your intention was, you have read my article, you have thought of what you might find interesting. Tell me what you would want, and then we can figure out together whether this makes sense. Let’s write an article about this interview and see how we can understand and try to embrace the legitimacy of each other’s approach, in terms of knowledge production”
On appreciating new approaches: “I learned about tools that I didn’t know existed, that do things I didn’t know could be done, that answer questions that I hadn’t even thought about asking and that I had no awareness that I might be interested in.” Joel Morley
 Some relaxing in the park after the intens, useful and very pleasant OH workshop in München
Some relaxing in the park after the intens, useful and very pleasant OH workshop in München
Acknowledgement
We would like to thank our workshop organiser and sessions lead colleagues for contributing to this blog text:
Arjan van Hessen, Norah Karrouche, Jeannine Beeken, Maureen Haaker, Max Broekhuisen and Christoph Draxler.
Moreover, we are very grateful to CLARIN ERIC for the opportunity to hold this workshop (and the previous ones).
Location
 The workshop was hold at the 4th floor in the beautifull
The workshop was hold at the 4th floor in the beautifull
Lehrturm of the Ludwig-Maximilians-Universität in the centre of München.
